在CPU平台上优化GEMM算子(General Matrix Multiply,即通用矩阵乘法)需要深入理解并发编程、硬件架构以及计算优化技术。优化的方法主要有三个方向:算法优化,循环展开和数据局部性优化。
算法优化:选择适合的矩阵分解算法,如Strassen算法或Karatsuba算法,可以减少矩阵乘法的时间复杂度。在对应的硬件平台下,需要选择最优的算法。
循环展开(Loop Unrolling):矩阵乘法涉及三重循环,这会导致CPU在执行循环判断和跳转指令上花费大量时间。通过循环展开,可以减少循环次数,从而减少CPU执行循环判断和跳转指令的时间。
数据局部性优化:矩阵乘法涉及大量的数据读取,如果能优化数据读取顺序,使得一次读取的数据能在接下来的计算中多次使用,可以减少数据读取次数,从而提高运行效率。一种常用的方法是使用Blocking技术,将大矩阵划分成多个小块,然后依次对小块进行处理,这样可以充分利用CPU缓存,提高数据的局部性。
以下是一个简单的优化示例: C++Copy code // 原始的矩阵乘法 void matmul_original(double* A, double* B, double* C, int N) { for (int i = 0; i < N; ++i) { for (int j = 0; j < N; ++j) { for (int k = 0; k < N; ++k) { C[i*N+j] += A[i*N+k] * B[k*N+j]; } } } } // 使用Loop Unrolling和Blocking的优化版本 #define BLOCK_SIZE 16 void matmul_optimized(double* A, double* B, double* C, int N) { for (int i = 0; i < N; i += BLOCK_SIZE) { for (int j = 0; j < N; j += BLOCK_SIZE) { for (int k = 0; k < N; k += BLOCK_SIZE) { // 在每个block内部进行计算 for (int ii = i; ii < i + BLOCK_SIZE; ++ii) { for (int jj = j; jj < j + BLOCK_SIZE; ++jj) { double sum = 0.0; for (int kk = k; kk < k + BLOCK_SIZE; ++kk) { sum += A[ii*N+kk] * B[kk*N+jj]; } C[ii*N+jj] += sum; } } } } } } 以上都是优化的一些基本思路,实际情况下可能需要根据具体的硬件架构和问题规模进行更深入的优化。 除了以上提到的方法,还有其他的优化方法,例如向量化(Vectorization)、多线程并行计算等。 向量化(Vectorization):现代CPU支持向量化运算,即一次操作可以作用于多个数据,例如Intel的AVX指令集。在适当的条件下,使用这些指令集可以显著提高计算效率。在C++中可以通过编译器的指令自动向量化,也可以手动使用相关的函数库,如Intel的MKL库。 多线程并行计算:现代的CPU通常有多个核心,可以同时执行多个线程。通过多线程并行计算,可以在多个核心上同时进行矩阵乘法的计算,从而提高计算效率。在C++中可以使用std::thread库创建多个线程进行并行计算。 以下是一个简单的使用多线程并行计算的例子: C++Copy code #include <thread> // 使用四个线程进行矩阵乘法 void matmul_parallel(double* A, double* B, double* C, int N) { auto worker = [&](int start, int end) { for (int i = start; i < end; ++i) { for (int j = 0; j < N; ++j) { for (int k = 0; k < N; ++k) { C[i*N+j] += A[i*N+k] * B[k*N+j]; } } } }; int num_threads = 4; std::vector<std::thread> threads; for (int i = 0; i < num_threads; ++i) { int start = i * N / num_threads; int end = (i + 1) * N / num_threads; threads.push_back(std::thread(worker, start, end)); } for (auto& t : threads) { t.join(); } } 当然,我们还可以采用一些其他更先进的技术和方法进行优化,比如SIMD指令、预取技术(Prefetching)以及用于性能调优的工具和框架等。 SIMD指令:SIMD是Single Instruction, Multiple Data的缩写,也就是单指令多数据流。现代的CPU提供了一系列的SIMD指令集,例如Intel的SSE和AVX系列,以及ARM的NEON等。通过SIMD,我们可以在单个操作中对多个数据项进行处理,进一步提高性能。 预取技术(Prefetching):预取是一种提前将数据从主存取到缓存的技术,以减少数据访问的延迟。对于GEMM这种内存访问较频繁的场景,预取可以显著提高性能。在C++中,可以使用__builtin_prefetch函数进行预取。 性能调优工具和框架:很多情况下,优化是一个反复试验和调整的过程。对于复杂的程序,可能需要借助性能调优工具来找出性能瓶颈,例如使用Intel的VTune,Google的gperftools等。另外,一些优化框架,例如OpenMP和OpenACC,也可以提供一些高层次的抽象,以简化并行编程的复杂性。 下面是一个简单的使用SIMD和预取进行优化的例子: C++Copy code #include <immintrin.h> // for AVX // 使用AVX和预取进行矩阵乘法 void matmul_simd_prefetch(double* A, double* B, double* C, int N) { for (int i = 0; i < N; ++i) { for (int j = 0; j < N; ++j) { __m256d c = _mm256_setzero_pd(); for (int k = 0; k < N; k += 4) { // 预取 __builtin_prefetch(&A[i*N+k+16], 0, 3); __builtin_prefetch(&B[k*N+j+16], 0, 0); // 加载数据 __m256d a = _mm256_load_pd(&A[i*N+k]); __m256d b = _mm256_load_pd(&B[k*N+j]); // 计算 c = _mm256_add_pd(c, _mm256_mul_pd(a, b)); } // 存储结果 _mm256_store_pd(&C[i*N+j], c); } } } 注意:以上代码假定N是4的倍数,如果不是,可能需要额外处理边界情况。 请注意,这些方法可能需要深入了解底层硬件架构和编程模型,以及如何使用相关的工具和库。对于更复杂的问题,可能需要进行更深入的分析和优化。 |


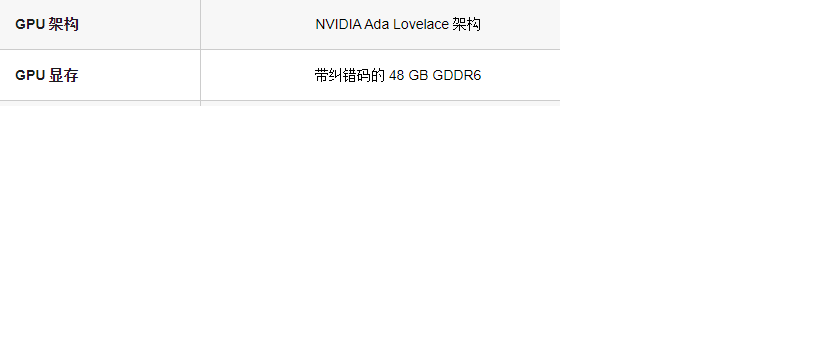

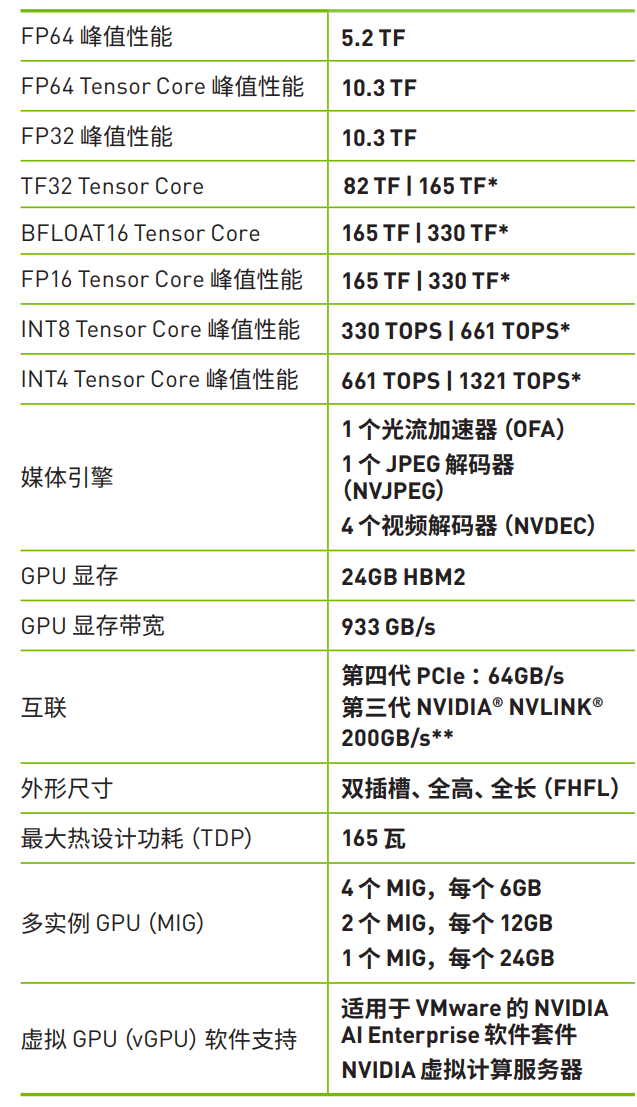




说点什么...