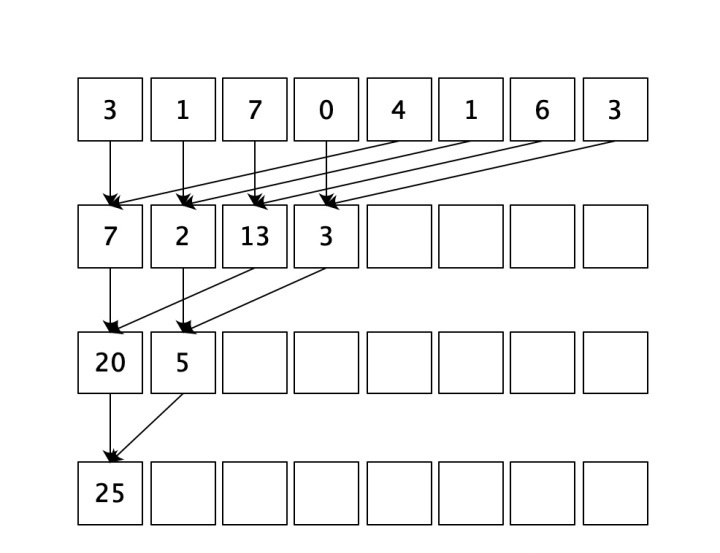
摘要:本文介绍了如何使用CUDA编程模型实现高效的数组归约算法,通过并行计算在GPU上对大规模数组进行求和操作。我们将逐步展示实现归约算法的过程,并介绍一些优化技巧,以提高计算性能。 1. 引言 归约算法是高性能计算中常用的一种算法,用于对大规模数组进行求和、求最大值、求最小值等操作。在传统的CPU计算中,归约算法是通过循环迭代逐个累加数组元素来实现的,这种串行计算方式在处理大规模数据时会非常耗时。为了加快计算速度,我们可以利用GPU的并行计算能力,使用CUDA编程模型实现高效的归约算法。 2. CUDA归约算法基本原理 CUDA归约算法的基本原理是将大规模数组划分成多个小块,在GPU上同时对每个小块进行归约操作,然后将每个小块的结果再归约为最终的结果。这样一来,我们可以充分利用GPU的并行计算能力,提高归约算法的计算速度。 3. CUDA归约算法实现步骤 3.1 数据准备 首先,我们需要将待求和的大规模数组拷贝到GPU的全局内存中。假设数组长度为N,我们可以将数组分割成若干个小块,每个小块的大小为blockSize。然后,我们需要在GPU上分配全局内存和共享内存,用于存储归约的中间结果。 ```cpp // 将数组拷贝到GPU的全局内存中 cudaMemcpy(d_array, h_array, N * sizeof(float), cudaMemcpyHostToDevice); ``` 3.2 并行归约计算 接下来,我们需要在GPU上进行并行归约计算。我们可以使用CUDA的核函数来实现并行计算。在核函数中,每个线程负责处理一个小块中的若干个元素,将这些元素归约为一个中间结果。然后,使用原子操作将每个线程的中间结果累加到全局内存中。 ```cpp __global__ void reduce(float* d_array, int N, int blockSize) { extern __shared__ float s_data[]; int tid = threadIdx.x; int bid = blockIdx.x; // 将每个线程处理的数据拷贝到共享内存中 int start = bid * blockSize; int end = start + blockSize; s_data[tid] = 0; for (int i = start + tid; i < end; i += blockDim.x) { s_data[tid] += d_array[i]; } // 使用原子操作将每个线程的中间结果累加到全局内存中 atomicAdd(&d_result, s_data[tid]); } ``` 3.3 归约结果 最后,我们需要将GPU上的归约结果拷贝回到CPU内存中。 ```cpp // 将GPU上的归约结果拷贝回到CPU内存中 float result; cudaMemcpyFromSymbol(&result, d_result, sizeof(float), 0); ``` 4. 优化技巧 在上述基本实现的基础上,我们还可以使用一些优化技巧来进一步提高归约算法的计算性能。 4.1 使用Warp级别的归约 在核函数中,我们可以使用Warp级别的归约来减少线程之间的同步开销。这样一来,每个Warp中的线程可以协同计算一个小块的归约结果,然后将这些结果再归约为一个中间结果。 4.2 使用全局内存和共享内存结合的方法 在核函数中,我们可以使用全局内存和共享内存结合的方法来减少全局内存访问次数,从而提高计算性能。具体方法是,每个Warp中的线程首先将数据从全局内存加载到共享内存中,然后在共享内存中进行归约计算,最后将结果写回到全局内存中。 5. 结论 通过使用CUDA编程模型实现高效的归约算法,我们可以充分利用GPU的并行计算能力,提高归约操作的计算速度。在实际应用中,我们还可以根据具体情况采取一些优化措施,进一步提高归约算法的性能。同时,我们还可以将归约算法与其他优化技术结合起来,进一步提高整体计算性能。 例如,我们可以将归约算法与SIMD(Single Instruction, Multiple Data)优化技术结合,使用SIMD指令集对数据进行并行处理,从而进一步加速归约计算。另外,我们还可以使用异步数据传输技术,将数据的传输与计算操作重叠,以减少数据传输的等待时间,从而提高整体的计算效率。 在实际应用中,我们需要根据具体的问题和硬件平台,灵活选择不同的优化技术,以达到最佳的性能优化效果。同时,我们还需要注意算法的正确性和稳定性,避免由于优化造成的计算结果错误或不稳定的情况。 综上所述,CUDA归约算法是一种高效的并行计算方法,通过利用GPU的并行计算能力,可以大大加快对大规模数组的求和、求最大值、求最小值等操作的计算速度。在实际应用中,我们可以结合各种优化技术,进一步提高算法的性能。通过不断优化和改进,我们可以更好地利用高性能计算技术,为科学研究和工程应用提供更快、更高效的计算支持。 |





说点什么...