据研究显示,大型语言模型GPT以其出色的语义理解和知识表达能力吸引全球瞩目。特别是基于GPT-4内核的新一代产品,引领了高性能计算方向的新趋势[1]。这不仅体现了超算/高性能计算的发展势头,也说明了全球政府、组织和企业正在积极参与这个行业。 GPT系列模型秉承了不断堆叠transformer的模型,这种方法依赖于海量的训练语料、大量的模型参数和强大的计算资源。该模型在自然语言处理、机器翻译、问答系统等复杂任务中展现出卓越的性能,从而为超算/高性能计算的未来发展开辟了新的可能性[2]。 然而,GPT-4等高性能计算模型的发展并非易事,需要大量的投资和计算资源。例如,GPT-3的费用,同时依赖于1,750亿的参数量和45TB的训练数据[2]。这种规模的模型是一般中小企业无法承受的,但这并未阻止政府、组织和大型企业对此进行投资和研究。 在全球范围越来越多的政府、组织和企业开始认识到超算/高性能计算的重要性并加大了投入。对于这些机构而言,将AI和大数据相结合,实现高性能计算,不仅可以提高工作效率,还可以提供更多创新的解决方案。 例如,医疗健康、气候模拟、科研计算等领域都开始使用超算/高性能计算技术。这些领域的发展,将进一步推动高性能计算技术的发展,同时也为政府、组织和企业带来新的商业机会。 总体来看,未来的社会将更加依赖于超算/高性能计算技术,政府、组织和企业的积极参与,无疑将推动这一领域的快速发展。在GPT等模型的推动下,我们有理由相信,这个基于算法、算力的时代,将会走向更为广阔的前景。 网络资料:[1] "非攻. 2022年11月,人工智能实验室OpenAI发布对话式大型语言模型ChatGPT。. 作为基于生成式预训练(Generative Pre-Training,GPT)技术迭代发展而来的应用产品,ChatGPT以其出色的语义理解和知识表达能力惊艳全球。. 尤其在基于GPT-4内核的新一代产品面世后,其对多模态 ..." URL: https://zhuanlan.zhihu.com/p/621659345 [2] "Generative Pre-trained Transformer(GPT)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的NLP任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A等,而完成这些任务并不需要有监督学习进行模型微调。而对于一个新的任务,GPT仅仅需要非常少的数据便可以理解这个任务的需求并达到接近或者超过state-of-the-art的方法。 当然,如此强大的功能并不是一个简单的模型能搞定的,GPT模型的训练需要超大的训练语料,超多的模型参数以及超强的计算资源。GPT系列的模型结构秉承了不断堆叠transformer的思想,通过不断的提升训练语料的规模和质量,提升网络的参数数量来完成GPT系列的迭代更新的。GPT也证明了,通过... See full list on zhuanlan.zhihu.com 在GPT-1之前(和ELMo同一年),传统的NLP模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点: 1. 需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,图像的标签并不是唯一的或者实例标签并不存在明确的边界; 2. 根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP。 这里介绍的GPT-1的思想是先通过在无标签的数据上学习一个生成式的语言模型,然后再根据特定热任务进行微调,处理的有监督任务包括 1. 自然语言推理(Natural Language Inference 或者 Textual Entailment):判断两个句子是包含关系(entailment),矛盾关系(cont... See full list on zhuanlan.zhihu.com 截止编写此文前,GPT-3是目前最强大的语言模型,仅仅需要zero-shot或者few-shot,GPT-3就可以在下游任务表现的非常好。除了几个常见的NLP任务,GPT-3还在很多非常困难的任务上也有惊艳的表现,例如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码等。而这些强大能力的能力则依赖于GPT-3疯狂的 1,750 亿的参数量, 45 TB的训练数据以及高达 1,200万美元的训练费用。 See full list on zhuanlan.zhihu.com GPT系列从1到3,通通采用的是transformer架构,可以说模型结构并没有创新性的设计。在微软的资金支持下,这更像是一场赤裸裸的炫富:1750亿的参数,31个分工明确的作者,超强算力的计算机( 285,000 个CPU, 10,000 个GPU),1200万的训练费用,45TB的训练数据(维基百科的全部数据只相当于其中的 0.6\\%)。这种规模的模型是一般中小企业无法承受的,而个人花费巨金配置的单卡机器也就只能做做微调或者打打游戏了。甚至在训练GPT-3时出现了一个bug,OpenAI自己也没有资金重新训练了。 读懂了GPT-3的原理,相信我们就能客观的看待媒体上对GPT-3的过分神话了。GPT-3的本质还是通过海量的参数学习海量的数据,然后依赖transformer强大的拟合能力使得... See full list on zhuanlan.zhihu.com Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. and Sutskever, I., 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8), p.9. Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Ka... See full list on zhuanlan.zhih |


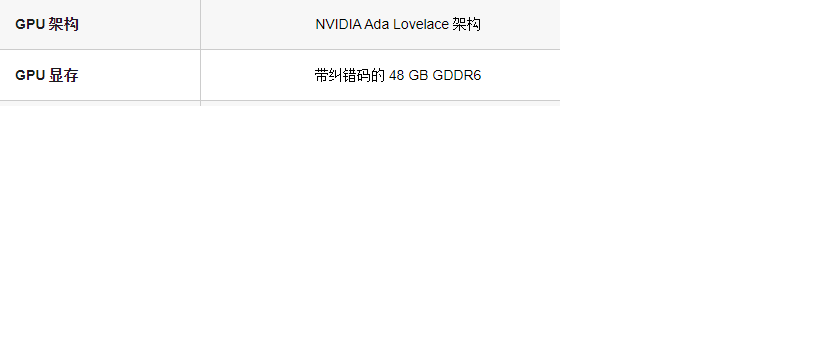

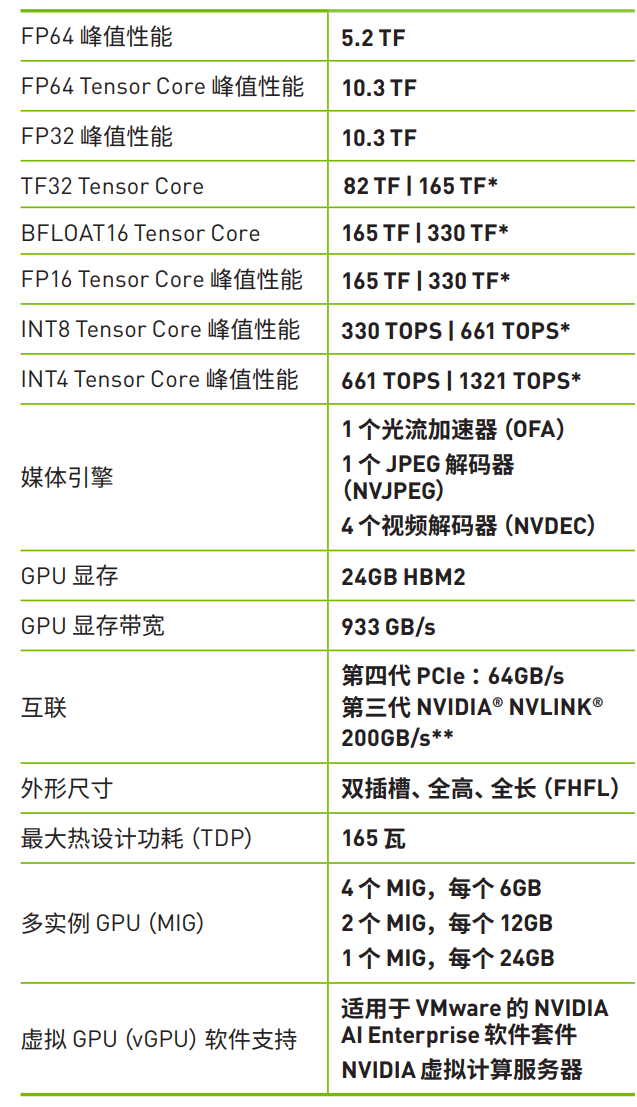




说点什么...