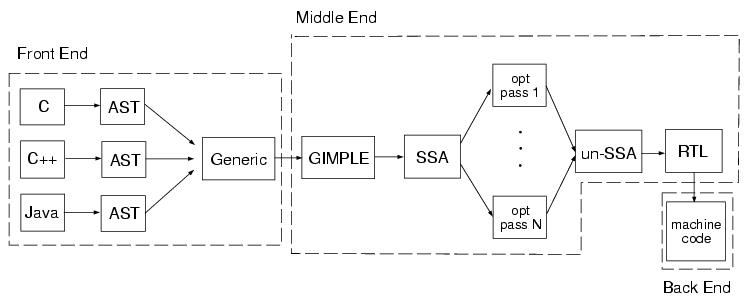
| GNU编译器集合(GCC)包括许多用于不同编程语言的编译器。GCC的主要可执行程序GCC处理用C、C++、Objective-C、Objective-C++、Java、Fortran或Ada编写的源文件,并为每个源文件生成一个汇编文件。它是一个驱动程序,根据源文件的语言调用适当的编译程序。对于C源文件,它们是预处理器和编译器cc1、汇编程序as和链接器collect2。第一个和第三个程序是GCC发行版,汇编程序是GNU binutils包的一部分。这本书描述了预处理器和编译器cc1的内部结构。 每个编译器包括以下三个组件:前端、中间端和后端。GCC一次编译一个文件。源文件一个接一个地遍历所有三个组件。图1展示了组件以及与每个组件相关联的源文件表示。
前端的目的是读取源文件,解析它,并将其转换为标准的抽象语法树(AST)表示。每种编程语言都有一个前端。由于语言的差异,每种语言生成的AST的格式略有不同。AST生成后的下一步是统一步骤,在该步骤中,AST树被转换为称为泛型的统一形式。在这之后,编译器的中端部分获得控制权。首先,将树转换为另一种称为GIMPLE的表示。在这种形式中,每个表达式包含不超过三个操作数,所有控制流结构都表示为条件语句和goto运算符的组合,函数调用的参数只能是变量等。图2说明了泛型形式的树和GIMPLE形式的树之间的区别。GIMPLE是优化源代码的方便表示。 在GIMPLE之后,源代码被转换为静态单分配(SSA)表示。这种形式的核心思想是,每个变量只分配一次,但可以在表达式的右侧多次使用。每次重新分配GIMPLE形式的树中的同一变量时,编译器都会创建该变量的新版本,并将新值存储到其中。当在条件表达式的两个分支中都分配了同一个变量时,需要将该变量的两个可能值合并为一个变量。此操作在SSA形式中表示为PHI函数。 SSA表单也用于优化。GCC对SSA树执行了20多种不同的优化。SSA优化通过后,树被转换回GIMPLE形式,然后用于生成树的寄存器转移语言(RTL)形式。RTL是一种基于硬件的表示,对应于具有无限数量寄存器的抽象目标体系结构。RTL优化过程以RTL形式优化树。最后,GCC后端使用RTL表示生成目标体系结构的汇编代码。后端的例子有x86后端、mips后端等。 在接下来的部分中,我们将描述C前端和x86后端的内部结构。编译器从初始化和命令行选项处理开始。之后,C前端对源文件进行预处理、解析并执行一些优化。然后,后端生成目标平台的程序集代码,并将其保存到文件中。 请注意:GCC是一个编译器集合,它由每种编程语言的前端、每种体系结构的中间端和后端组成。每个源文件经过的主要表示形式是前端的AST、中间端的RTL和后端的部件表示形式。GCC一次编译一个文件。 GCC InitializationC前端包括C/C++预处理器和C编译器。程序cc1包括预处理器和C编译器。它编译一个C源文件并生成一个程序集(-S)文件。 编译器前端和后端使用称为语言挂钩的回调函数进行交互。所有挂钩都包含在文件langhook.h中定义的全局变量结构lang_hooks lang_hook中。有以下类型的挂钩:树内联挂钩、调用图挂钩、函数挂钩、树转储挂钩、类型挂钩、声明挂钩和语言特定挂钩。钩子的默认值在文件langhookdef.h中定义。 GCC初始化包括命令行选项解析、初始化后端、创建全局范围以及初始化内置数据类型和函数。 每个声明都与一个作用域相关联。例如,局部变量与其函数的作用域相关联。全局声明与全局范围相关联。 函数toplev_main()是处理命令行选项、初始化编译器、编译文件并释放分配的资源的函数。函数decode_options()处理命令行选项,并在编译器中设置相应的变量。 按照命令行选项,将调用解析函数do_compile()。它通过调用函数backend_init()来执行后端初始化。之后,函数lang_dependent_init()执行与语言相关的初始化,其中包括前端和后端的初始化。C初始化函数C_objc_common_init()创建内置数据类型,初始化全局作用域并执行其他初始化任务。函数c_common_nodes_and_builtins()创建内置文件types.def中描述的预定义类型。 标准的C类型是在初始化时创建的。下表列出了几种类型:
GCC内置函数是在编译时评估的函数。例如,如果strcpy()函数的size参数是常量,则GCC将用所需数量的赋值替换函数调用。编译器用内置函数替换标准库调用,然后在构建函数的AST后对其进行求值。在strcpy()的情况下,编译器会检查大小参数,如果参数是常量,则会使用优化的内置版本的strcpy。Builtin Builtin_constant_p()允许在编译时发现其参数的值是否已知。GCC内建在GCC之外使用。例如,如果在编译时字符串大小已知,那么Linux内核的字符串处理库将使用内置_constant_p()来调用字符串处理函数的优化版本。 GCC使用相应的expand_buillin()函数来评估每个内置函数。例如,使用expand_builtin_strcmp()对内置_strcmp进行求值。下表给出了GCC内置的示例:
注意:GCC初始化包括命令行选项解析、初始化后端、创建全局范围以及初始化内置数据类型和函数。 C Preprocessor初始化之后,函数do_compile()调用函数compile_file()。此函数调用parse_file()前端语言挂钩,该挂钩设置为c语言的函数c_common_parse_file(。后一个函数调用函数finish_options(),该函数初始化预处理器并处理-D、-U和-A命令行选项(分别相当于#define、#undef和#assert)。C预处理器处理源代码中的预处理器指令,如#define、#include。 在预处理器初始化之后,将调用c_parse_file()函数。此函数使用标准的lex/bison工具来解析文件。预处理器是作为lexer的一部分来实现的。C语言lexer函数C_lex()调用处理预处理器关键字的libcpp函数cpp_get_token()。预处理器的状态由变量cpp_reader*parse_in定义。类型struct cpp_reader最重要的是包含正在处理的文本缓冲区列表。每个缓冲区对应一个源文件(.c或.h)。函数cpp_get_token()为合法的预处理器关键字调用适当的函数。例如,当遇到#include时,会调用函数do_include_common()。它分配一个新的缓冲区,并将其放在缓冲区堆栈的顶部,使其成为当前缓冲区。编译新文件时,缓冲区会从堆栈中弹出,并继续编译旧文件。 每当使用#define关键字定义新宏时,都会调用函数do_define()。 带回家:预处理器处理预处理器指令,例如#include和#ifdef。 Source Code Parsing在运行预处理器之后,GCC为源文件的每个函数构造一个抽象语法树(AST)。AST是结构树类型的多个连接节点。每个节点都有一个树代码,用于定义树的类型。宏TREE_CODE()用于引用代码。树代码在文件Tree.def和c-common.def中定义。具有不同树代码的树被分组到树类中。GCC中定义了以下树类:
树有两种类型:语句和表达式。语句对应于C结构,例如后面跟着“;”的表达式,条件语句、循环语句等。表达式是构建语句的基础。表达式的示例有赋值表达式、算术表达式、函数调用等。下表中给出了树代码的示例:
除了定义树类型的树代码外,还提供了许多针对每种树类型不同的操作数。例如,赋值表达式有两个操作数,分别对应于表达式的左侧和右侧。宏TREE_OPERAND用于引用操作数。宏IDENTIFIER_POINTER用于查找IDENTIFIER_NODE树所表示的标识符的名称。下表显示了几个树节点、它们的用途以及它们的操作数。 每个树都有一个与它所表示的C表达式类型相对应的类型。例如,MODIFY_EXPR节点的类型是左侧操作数的类型。NOP_EXPR和CONVERT_EXPR树用于类型转换。 树NULL_Tree等效于NULL。函数debug_tree()将树打印到stderr。 解析器被实现为野牛语法。语法调用构造AST的GCC函数。当一个新的标识符被lexed时,它被添加到GCC维护的字符串池中。标识符的树代码是identifier_NODE。当再次对相同的标识符进行lexed时,将返回相同的树节点。函数get_identifier()返回标识符的树节点。 一个新的变量声明在许多函数调用中进行处理。首先,使用声明的名称、lexer返回的类型及其属性来调用函数start_decl()。该函数调用grokdeclator(),该函数检查类型和参数节点,并返回一个树,其中包含适用于声明的代码:变量为VAR_DECL,类型为type_DECL等。然后将声明添加到作用域中。作用域包含在函数内创建的所有声明,但不包含全局声明。还有一个包含全球声明的全球范围。解析函数时,其声明作为BLOCK节点附加到其主体。创建声明时,使用identifier_SYMBOL_VALUE将标识符节点与声明节点相关联。函数lookup_name()返回给定标识符的声明。当声明离开作用域时,将断言树属性C_DECL_INVISIBLE。 GCC中不维护符号表。相反,编译器使用标识符池和C_DECL_INVISIBLE属性。语言挂钩lang_hooks.decls.getdecls()返回链接在一起的作用域中的变量。 函数start_init()和finish_init(。函数finish_decl()完成声明。对于数组声明,它计算初始化数组的大小。然后调用函数layout_decl()。它计算声明的大小和对齐方式。 解析函数取决于函数体的存在。函数声明使用与变量声明相同的函数进行解析。对于函数定义,调用函数start_function()。然后编译器解析函数的主体。当函数结束时,将调用函数finish_function()。 函数start_decl()和start_function()将声明的attributes参数作为其参数之一。GCC手册中对这些属性进行了说明。属性是C的GNU实现的扩展。下表列出了其中的一些属性并解释了它们的用途:
对于每种类型的C语句,都有一个函数来构造相应类型的树节点。例如,函数build_function_call()为函数调用构建call_EXPR节点。它将函数名称的标识符和参数作为其参数。该函数使用lookup_name()查找函数声明,并使用default_conversion()类型强制转换参数。 然后将AST转换为SSA,并最终转换为RTL表示。无论转换是在解析每个函数后发生,还是在解析整个文件时发生,都由编译器选项-funcit-at-a-time控制。默认情况下为false。 记住:GCC解析器是按照野牛语法编写的。它创建源文件的AST表示。AST是由树节点组成的。每个节点都有一个代码。树节点对应于C的语句和表达式。函数debug_Tree()打印出树。 Assembly Code Generation后端为指定的目标平台生成程序集代码。为写入汇编文件的每条指令调用函数output_asm_insn()。函数final_start_Function()在将函数保存到程序集文件之前生成该函数的序言。 |









说点什么...